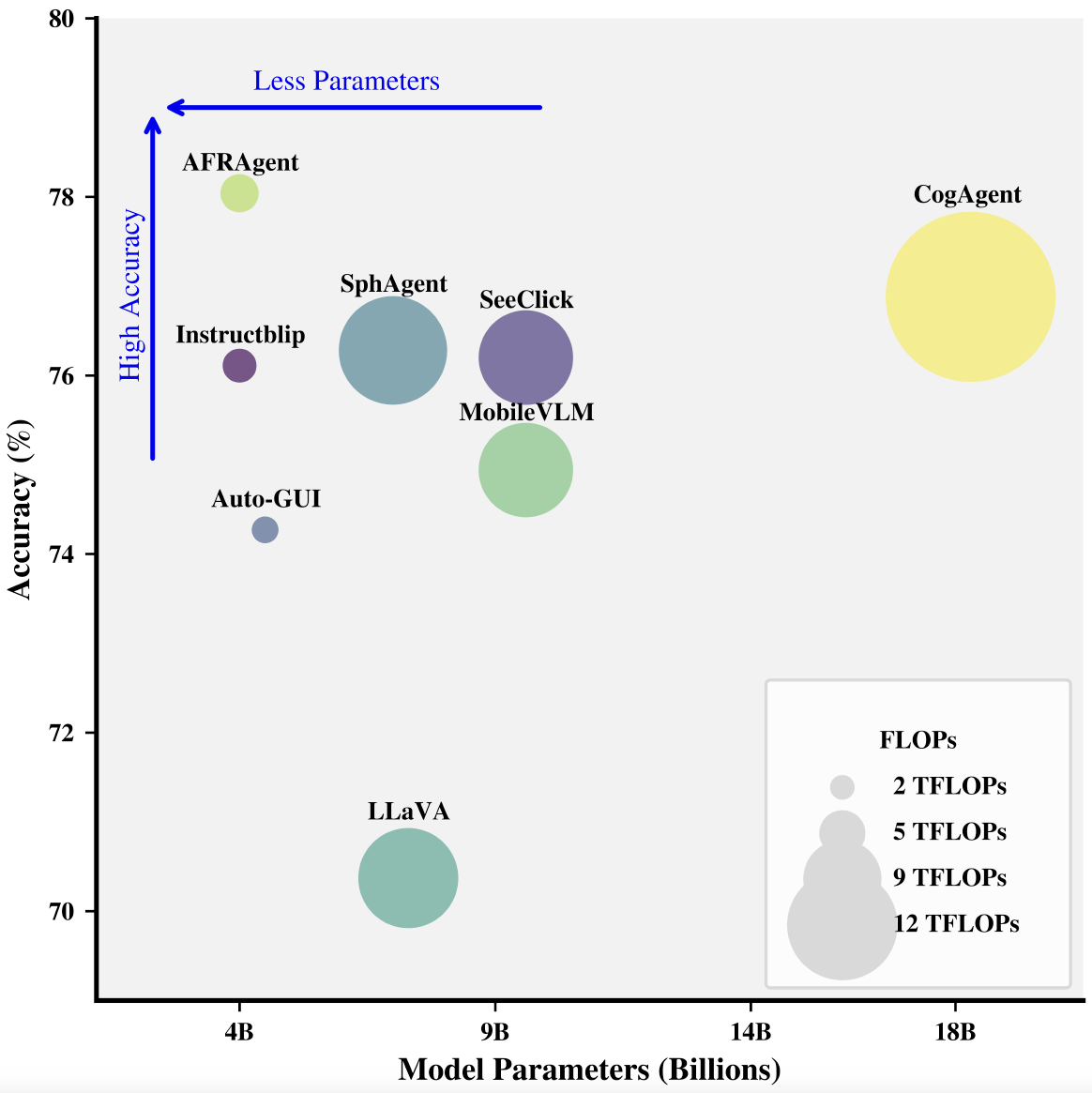
 AFRAgent achieves state-of-the-art performance on GUI automation benchmarks while being less than one-fourth the size of its nearest competitor. The model uses Adaptive Feature Renormalization (AFR) to inject high-resolution visual details into Q-Former features efficiently.
AFRAgent achieves state-of-the-art performance on GUI automation benchmarks while being less than one-fourth the size of its nearest competitor. The model uses Adaptive Feature Renormalization (AFR) to inject high-resolution visual details into Q-Former features efficiently.
Abstract
There is a growing demand for mobile user interface (UI) automation, driven by its broad applications across industries. With the advent of visual language models (VLMs), GUI automation has progressed from generating text-based instructions for humans to autonomously executing tasks, thus optimizing automation workflows. Recent approaches leverage VLMs for this problem due to their ability to process on-screen content directly, remain independent of device-specific APIs by utilizing human actions (e.g., clicks, typing), and apply real-world contextual knowledge for task understanding. However, these models often have trouble accurately identifying widgets and determining actions due to limited spatial information in vision encoder features. Additionally, top-performing models are often large, requiring extensive training and resulting in inference delays.
In this work, we introduce AFRAgent, an InstructBLIP-based multimodal architecture that achieves superior performance in GUI automation while being less than one-fourth the size of its nearest competitor. To enhance image embeddings in the large language model (LLM) pipeline, we propose an Adaptive Feature Renormalization (AFR) technique—a token-level affine transformation that effectively enriches low-resolution image embeddings and fuses high-resolution details. We evaluate AFRAgent on Meta-GUI and AITW benchmarks, establishing a new state-of-the-art baseline for smartphone automation. Importantly, we fine-tune our model without any UI pretraining, unlike CogAgent, SeeClick, and SphAgent, demonstrating the robustness of our approach.
Network Architecture
 Core architectural improvements in AFRAgent: (1) BLIP vision encoder creates patch embeddings from the screenshot, (2) Q-Former produces instruction-aware query token features through cross-attention and self-attention layers, (3) AFR block computes token-wise scaling (α) and shifting (β) parameters from image embeddings to renormalize Q-Former outputs, (4) For high-resolution processing, the screenshot is divided into crops and processed through BLIP encoder, (5) High-res crops cross-attend with Q-Former using separate learnable queries, (6) High-res Q-Former features further enrich the low-res features via another AFR block, (7) Final enriched features are projected to the LLM for action prediction. See Figure 2 in the paper for the complete pipeline.
Core architectural improvements in AFRAgent: (1) BLIP vision encoder creates patch embeddings from the screenshot, (2) Q-Former produces instruction-aware query token features through cross-attention and self-attention layers, (3) AFR block computes token-wise scaling (α) and shifting (β) parameters from image embeddings to renormalize Q-Former outputs, (4) For high-resolution processing, the screenshot is divided into crops and processed through BLIP encoder, (5) High-res crops cross-attend with Q-Former using separate learnable queries, (6) High-res Q-Former features further enrich the low-res features via another AFR block, (7) Final enriched features are projected to the LLM for action prediction. See Figure 2 in the paper for the complete pipeline.
Key technical contributions:
- Adaptive Feature Renormalization (AFR): AFR takes two inputs—enriching features (Fenrich) and target features (Ftarget). It predicts scaling (α) and shifting (β) parameters via small feed-forward networks, then computes Fenriched = (α ⊙ Ftarget) ⊕ β. This token-level affine transformation effectively injects global and high-resolution visual cues into each Q-Former token without drastically increasing the LLM token count.
- Low-resolution enrichment: Image embeddings (It) from the BLIP encoder serve as enriching features that modulate the Q-Former query representations (EQ(Z)) through the AFR block, producing enriched features EQImage that combine direct projection benefits with Q-Former's task-aware representations.
- High-resolution enrichment: The screenshot is divided into C crops (4 horizontal sections to preserve aspect ratio), each processed through the BLIP encoder and Q-Former with separate high-resolution learnable query tokens. The resulting high-res Q-Former features are used to further enrich the low-res features via another AFR block, producing the final enriched representation EQHigh.
- Efficiency and practicality: AFRAgent uses only ~4B parameters (257 query tokens, dQ=768, LLM hidden size 2048) and achieves state-of-the-art results without expensive UI-specific pretraining. AFRAgent Low-res operates at ~3.2 TFLOPs (0.78s latency), while AFRAgent High-res adds minimal overhead at ~5.47 TFLOPs (1.24s), both substantially more efficient than larger baselines like CogAgent (11.86 TFLOPs, 3.42s).
Results
 AFRAgent achieves state-of-the-art or highly competitive performance on Meta-GUI and AITW benchmarks while using significantly fewer parameters and lower computational overhead than prior methods. See Tables 1-2 in the paper for detailed comparisons.
AFRAgent achieves state-of-the-art or highly competitive performance on Meta-GUI and AITW benchmarks while using significantly fewer parameters and lower computational overhead than prior methods. See Tables 1-2 in the paper for detailed comparisons.
Key results and highlights:
- Meta-GUI benchmark: AFRAgent achieves the highest completion rate (90.83%) among all methods, with a 2.56% improvement over the previous best. The model also shows a substantial 3.34% improvement in target item prediction accuracy (95.06% vs 91.72%) and strong performance across direction accuracy (97.02%), input text F1 (97.94%), and exact match (94.44%) metrics. These results demonstrate superior task comprehension despite having only 4B parameters compared to competitors with 7B+ parameters (Table 1).
- AITW benchmark - Pure Multimodal Setting: In the purely multimodal setting (using only screenshots and natural language goals without external layout tools), AFRAgent achieves the best overall accuracy (78.01%) among all methods, outperforming much larger models including CogAgent (18.3B parameters, 76.88%), SphAgent (7B, 76.28%), and SeeClick (9.6B, 76.2%). Despite being 78% smaller than CogAgent, AFRAgent excels across multiple task categories including General (70.67%), Install (80.89%), and WebShopping (73.27%) splits (Table 2).
- AITW benchmark - Structured Layout Setting: When layout information is available, AFRAgent remains competitive (78.92%) with CoCo-Agent (79.05%) while requiring significantly less memory overhead, as it doesn't rely on lengthy layout tokens (~1600 extra tokens/screen) that are prone to error propagation and limit cross-platform generalization.
- Computational efficiency: AFRAgent Low-res achieves ~3× faster inference (0.78s vs 3.42s) with 54% fewer FLOPs compared to CogAgent. Even AFRAgent High-res (1.24s, 5.47 TFLOPs) remains substantially more efficient than CogAgent while maintaining superior accuracy. The efficiency gains come from AFR's lightweight fusion mechanism that enriches features without passing excessive tokens to the LLM (Table 4).
- Cross-platform generalization: On the ScreenSpot benchmark, AFRAgent demonstrates strong generalization to web and desktop platforms (55.61% average accuracy), outperforming CogAgent (47.4%) and achieving competitive results with SeeClick (53.4%) despite SeeClick's more extensive GUI-specific pretraining (Table 3).
- Ablation studies: Comprehensive ablations (Table 5) show that AFR consistently outperforms alternative fusion strategies including residual connections and Mixture of Experts (MoE) approaches in both low-res and high-res settings. Grad-CAM visualizations (Figure 4) demonstrate that AFR effectively focuses model attention on task-relevant UI elements after feature enrichment.
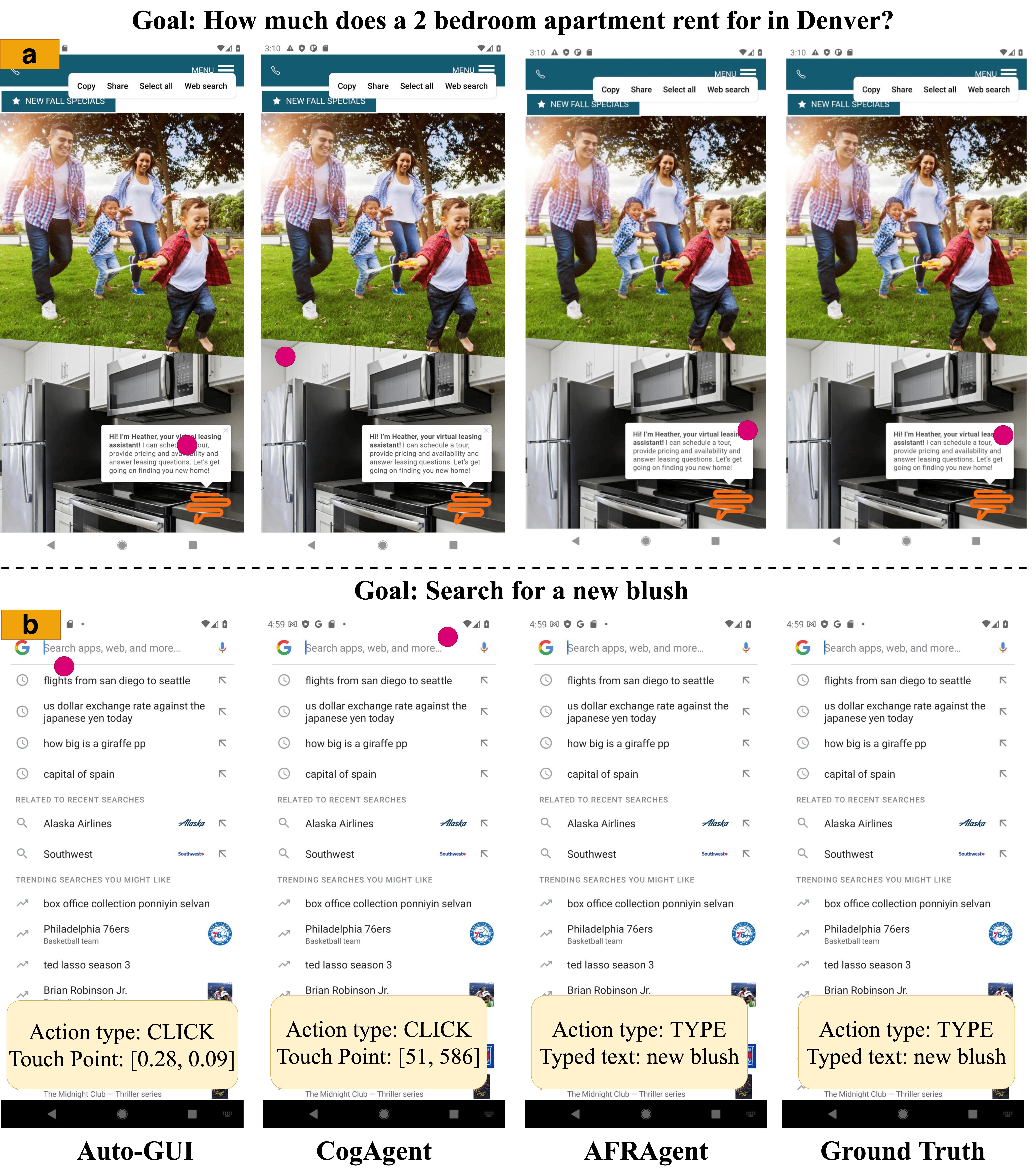
Figure 3 in the paper provides qualitative examples showing AFRAgent's superior spatial awareness: (a) accurately identifying a close icon in a pop-up window, and (b) correctly predicting both the action and input text "new blush" for a search task, where other methods failed.
Resources
- Paper (arXiv): arXiv:2512.00846v1
- Code Repository: Coming soon
Citation
@article{anand2024afragent,
title={{AFRAgent}: An Adaptive Feature Renormalization Based High Resolution Aware GUI agent},
author={Anand, Neeraj and Jain, Rishabh and Patnaik, Sohan and Krishnamurthy, Balaji and Sarkar, Mausoom},
journal={arXiv preprint arXiv:2512.00846},
year={2024}
}