 To remedy the shortcomings of single view person image generation, we propose merging information from multiple source
images. In Multi-view Human Reposing, given multiple images of a person, we generate a new image in the desired target pose. In Mix and Match Human Image Generation, we model all of the images in a tuple (id, top, bottom, pose) jointly to synthesise the final output
To remedy the shortcomings of single view person image generation, we propose merging information from multiple source
images. In Multi-view Human Reposing, given multiple images of a person, we generate a new image in the desired target pose. In Mix and Match Human Image Generation, we model all of the images in a tuple (id, top, bottom, pose) jointly to synthesise the final output
Abstract
Numerous pose-guided human editing methods have been explored by the vision community due to their extensive practical applications. However, most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. This objective becomes ill-defined in cases when the target pose differs significantly from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse knowledge from multiple viewpoints, we design a multi-view fusion network that takes the pose key points and texture from multiple source images and generates an explainable perpixel appearance retrieval map. Thereafter, the encodings from a separate network (trained on a single-view human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on two newly proposed tasks - Multi-view human reposing and Mix&Match Human Image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a better alternative.
Network architecture
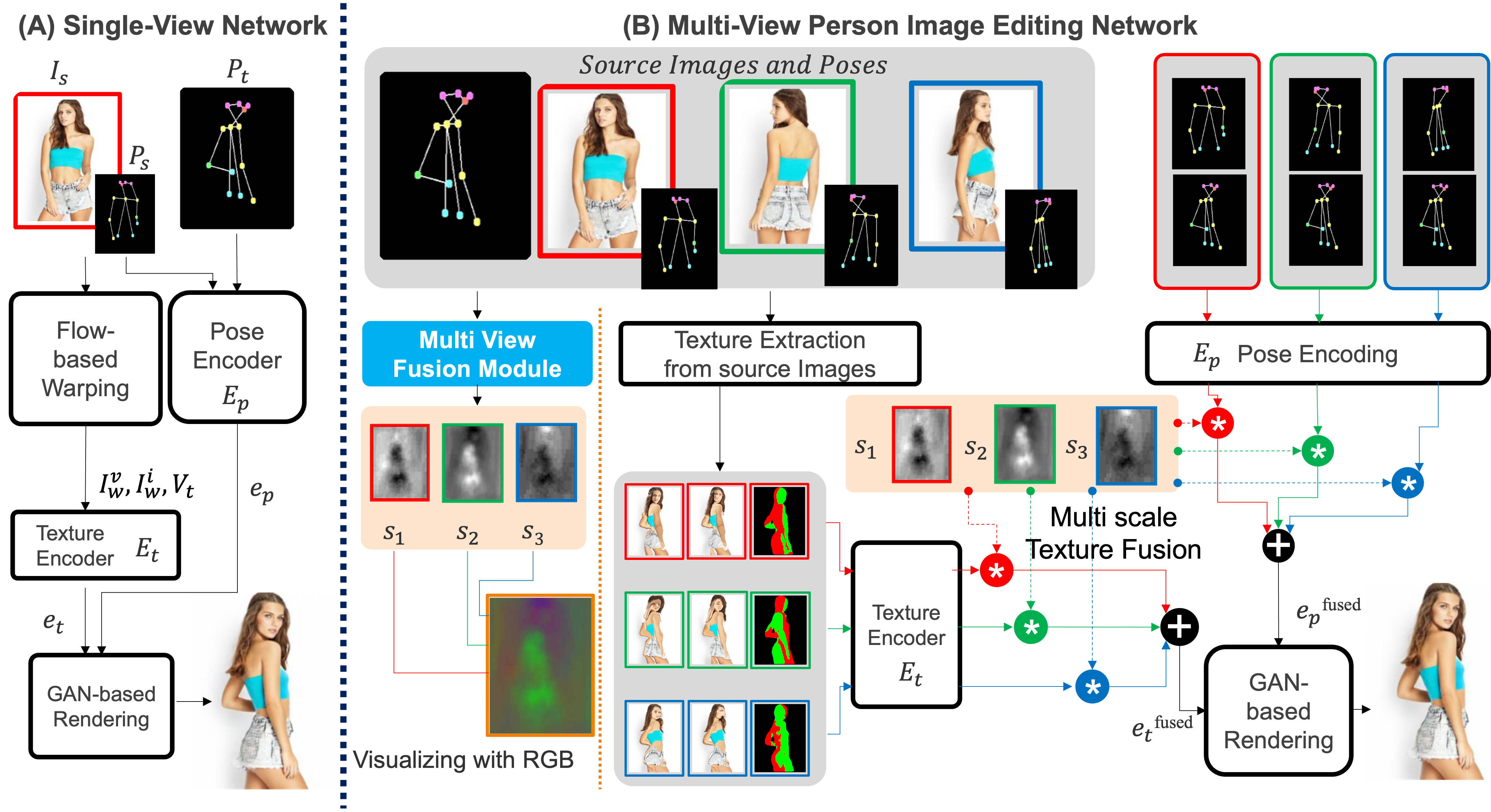 UMFuse framework: (A) is the single view PHIG network on top of which the UMFuse framework operates. The source image
and its keypoints along with the target keypoints are used to produce warped images and a visibility map (Iwv ,Iwi
,Vt). These are used to
obtain the texture encoding at different scales l (et,l), and the source and target poses are used to obtain the pose encoding ep. Together
they are used to render the output with a GAN-based renderer. (B) Shows the UMFuse adaptation for the single view network. The
multiple source images and poses are passed individually to the warping and visibility prediction module to obtain multiple warped images
and visibility maps, and from those, multiple texture-encoding vectors. Likewise, the source poses paired with the target pose are used to
obtain multiple pose encoding vectors. These are merged in an affine combination using the predicted Appearance Retrieval Maps(s1-3).
These maps are obtained using the Multi-view Fusion module and are a key contribution of the UMFuse framework.
UMFuse framework: (A) is the single view PHIG network on top of which the UMFuse framework operates. The source image
and its keypoints along with the target keypoints are used to produce warped images and a visibility map (Iwv ,Iwi
,Vt). These are used to
obtain the texture encoding at different scales l (et,l), and the source and target poses are used to obtain the pose encoding ep. Together
they are used to render the output with a GAN-based renderer. (B) Shows the UMFuse adaptation for the single view network. The
multiple source images and poses are passed individually to the warping and visibility prediction module to obtain multiple warped images
and visibility maps, and from those, multiple texture-encoding vectors. Likewise, the source poses paired with the target pose are used to
obtain multiple pose encoding vectors. These are merged in an affine combination using the predicted Appearance Retrieval Maps(s1-3).
These maps are obtained using the Multi-view Fusion module and are a key contribution of the UMFuse framework.
Results
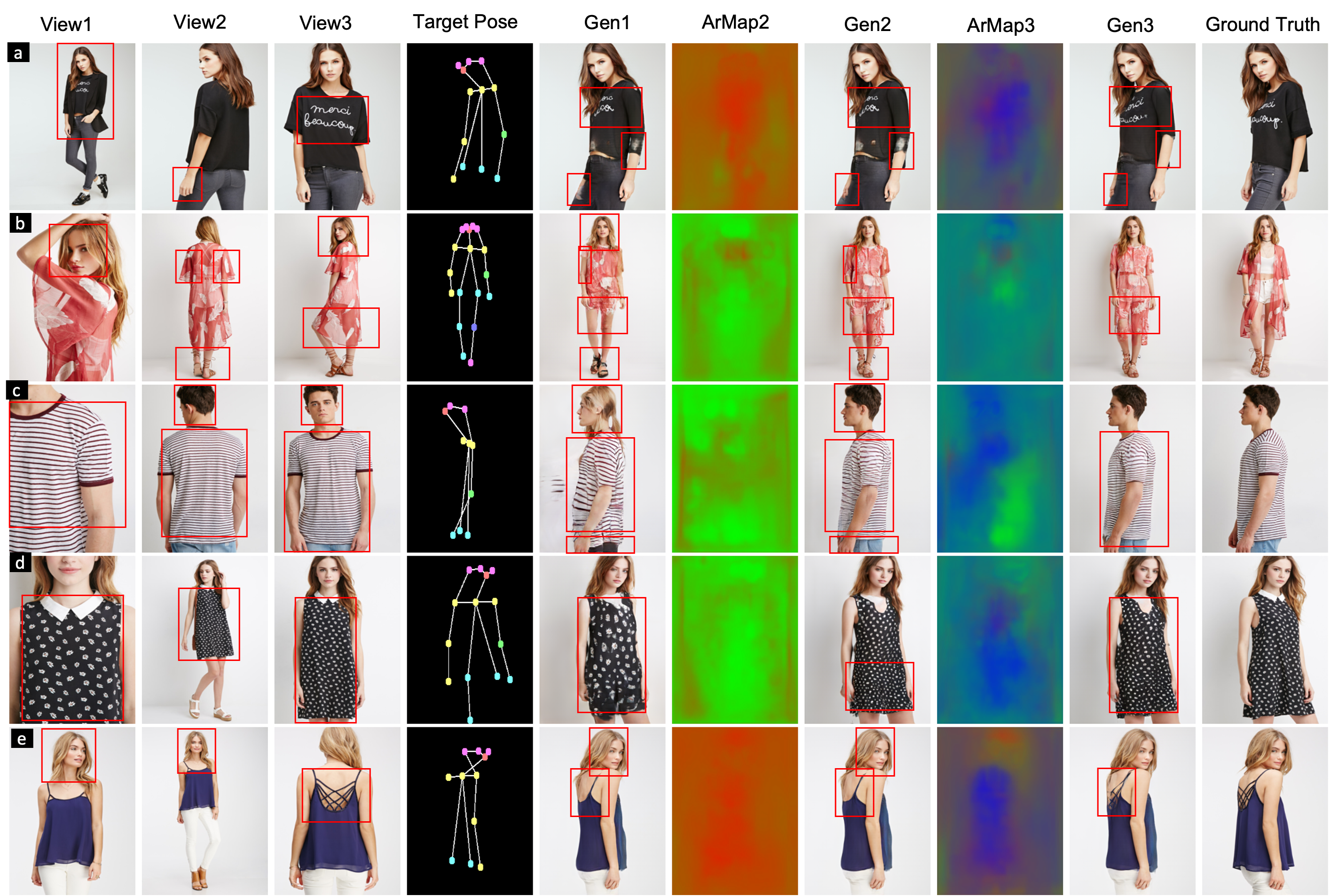 Here, we show incremental improvements gained by the network after the addition of multiple images. Gen1 is generated using
only View1 (repeated thrice). Gen2 is generated using View1 and View2 pair with ArMap2 showing the attribution map using red and
green colors respectively. Gen3 is obtained using all the 3 images and ArMap3 encodes the weights in RGB respectively.
Here, we show incremental improvements gained by the network after the addition of multiple images. Gen1 is generated using
only View1 (repeated thrice). Gen2 is generated using View1 and View2 pair with ArMap2 showing the attribution map using red and
green colors respectively. Gen3 is obtained using all the 3 images and ArMap3 encodes the weights in RGB respectively.
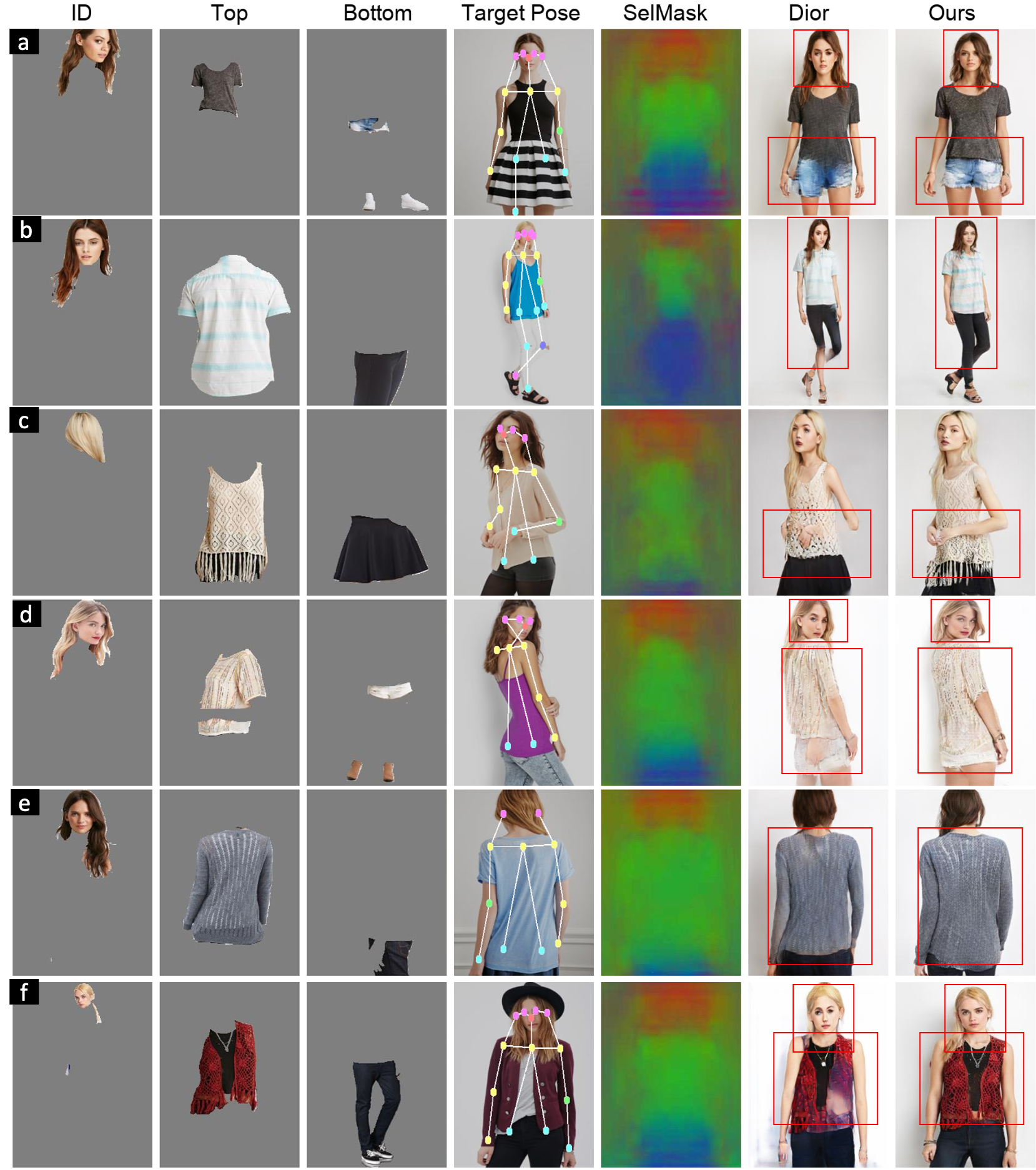 Qualitative Results for Mix & Match Human Image Generation showing realistic generation quality while preserving bodyshape(a),
modelling complex pose(b), complicated design and texture of cloth(c), heavy occlusions(d), missing information(e), multiple clothing garments with accessories(f).
Additional results can be found in the supplemental material
Qualitative Results for Mix & Match Human Image Generation showing realistic generation quality while preserving bodyshape(a),
modelling complex pose(b), complicated design and texture of cloth(c), heavy occlusions(d), missing information(e), multiple clothing garments with accessories(f).
Additional results can be found in the supplemental material
Resources
- Paper: ICCV
- Supplementary: ICCV_supplementary
- Video: YouTube
- Datasplit and Results for comparison: Zip file
Citation
@inproceedings{jain2023umfuse,
title={UMFuse: Unified Multi View Fusion for Human Editing applications},
author={Jain, Rishabh and Hemani, Mayur and Ceylan, Duygu and Singh, Krishna Kumar and Lu, Jingwan and Sarkar, Mausoom and Krishnamurthy, Balaji},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={7182--7191},
year={2023}
}