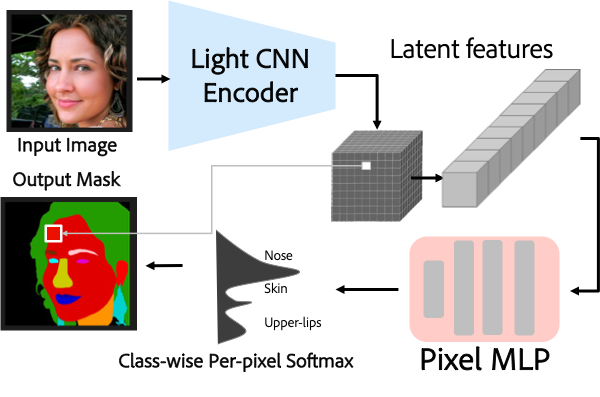
 The simple architecture of Local Implicit Image representation base FP-LIIF: A light convolutional encoder of modified
resblocks followed by a pixel only MLP decoder
The simple architecture of Local Implicit Image representation base FP-LIIF: A light convolutional encoder of modified
resblocks followed by a pixel only MLP decoder
Abstract
Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.
Network architecture
 Encoder Architecture: It has three res-block groups. The first two (2,6) res-block groups, followed by a strided conv per group,
are mainly used to reduce the spatial dimensions of the activation maps. The final group of res-blocks creates the grid of features vectors
Z. Notice each res-block group has a group-level residual connection.
Encoder Architecture: It has three res-block groups. The first two (2,6) res-block groups, followed by a strided conv per group,
are mainly used to reduce the spatial dimensions of the activation maps. The final group of res-blocks creates the grid of features vectors
Z. Notice each res-block group has a group-level residual connection.
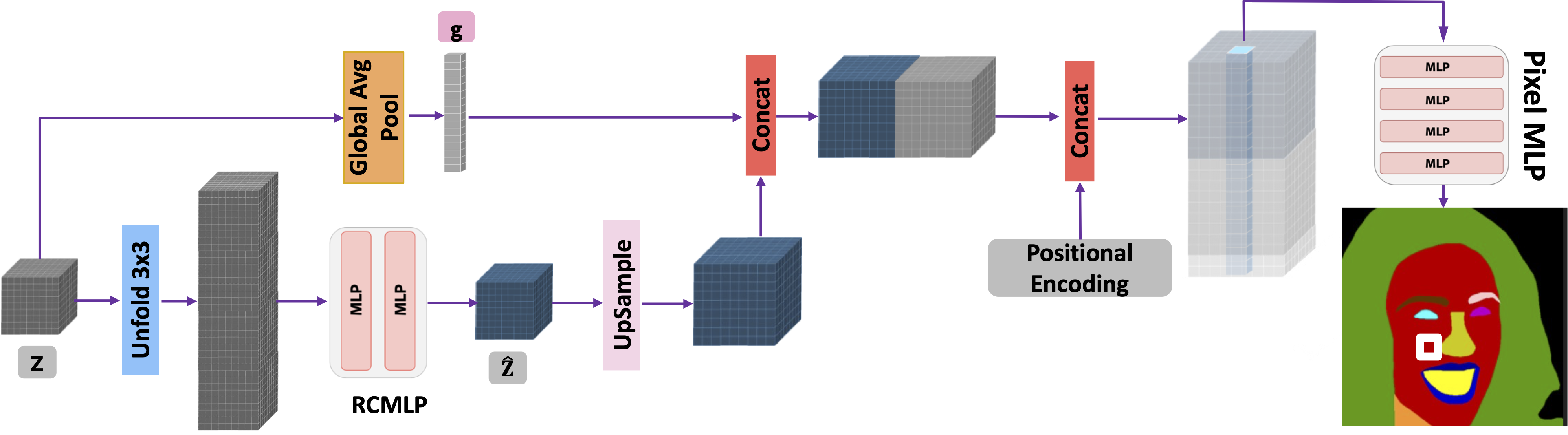 Decoder Architecture: Our decoder takes in the feature grid Z from the encoder and performs unfolding and global avg-pooling
as shown in the figure. A two layer fully connected MLP is used to bring down the number of channels in the unfolded volume. This is
upsampled and concatenated with global pool feature g and positional encoding. Finally a four layer MLP is applied per spatial location to
generate the class-wize probability distribution.
Decoder Architecture: Our decoder takes in the feature grid Z from the encoder and performs unfolding and global avg-pooling
as shown in the figure. A two layer fully connected MLP is used to bring down the number of channels in the unfolded volume. This is
upsampled and concatenated with global pool feature g and positional encoding. Finally a four layer MLP is applied per spatial location to
generate the class-wize probability distribution.
Results
 Visualization of a few results in CelebAMask-HQ
dataset. The difference between DML CSR and our results are
highlighted. The cloth region in a), b), eyes in b),c) d) and nose in
d),e) are better predicted by FP-LIIF
Visualization of a few results in CelebAMask-HQ
dataset. The difference between DML CSR and our results are
highlighted. The cloth region in a), b), eyes in b),c) d) and nose in
d),e) are better predicted by FP-LIIF
Resources
- Paper: CVPR
Citation
@inproceedings{sarkar2023parameter,
title={Parameter Efficient Local Implicit Image Function Network for Face Segmentation},
author={Sarkar, Mausoom and Hemani, Mayur and Jain, Rishabh and Krishnamurthy, Balaji and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={20970--20980},
year={2023}}